学院新闻
college news

近日,中国人民大学信息学院金琴教授团队aim3多媒体计算实验室1篇长文被国际计算机视觉大会iccv 2023录用。国际计算机视觉大会(international conferenceon computer vision,简称iccv)是中国计算机学会(ccf)推荐的a类国际学术会议,每两年召开一次,今年是第19届会议。
论文第一作者是来自aim3多媒体计算实验室的2019级博士生胡安文。
论文介绍
explore and tell: embodied visual captioning in 3d environments
作者:胡安文,陈师哲,张良,金琴
通讯作者:金琴
论文概述:
视觉描述模型已经取得了不错的效果。为了充分描述一个场景,他们需要输入一个拍摄角度较好且捕捉到大部分信息的图片或视频。然而,在现实场景中,一张图或一段视频可能不能完美得包含场景中所有的关键信息。在这种情况下,被动接受输入的视觉描述模型就不能提供有效的场景描述。为了克服这样的限制,我们提出使得视觉描述模型具备自主探索环境的能力,设计了一个新颖且有挑战性的任务——“embodied captioning”(具身视觉描述)。具体来说,从一个3d场景的随机一个视角点出发,智能体需要在环境中自主探索以收集不同视角下拍摄的视觉信息,最后生成一个详细的段落描述来提到场景内所有的物体、属性以及位置关系,如图1。

图1:具身视觉描述示例
为了支持这个任务,我们基于kubric模拟器构建了一个数据集et-cap,其包含10k个多样化的3d场景,每个场景由多个物体组成,且由人工标注了良好视角标注以及段落场景描述。
针对该任务,我们提出了一个级联式的具身视觉描述模型cabot,如图2。
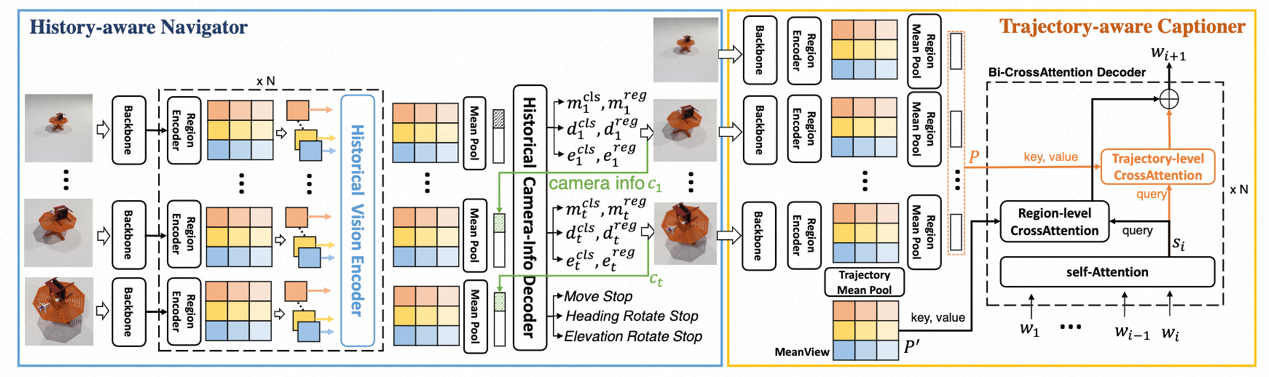
图2:cabot示意图
cabot由一个探索器和一个描述器组成,探索器根据历史视觉观测决定智能体下一步的移动动作,描述器则根据所有观测到的视觉信息生成场景描述。充分的实验证明我们提出的模型优于其它精心设计的基准方法。我们将会开源数据集、代码以及模型来促进具身视觉描述的发展。
作者简介
胡安文,中国人民大学信息学院2019级博士,大数据科学与工程专业,主要研究方向是图像描述生成,多模态预训练。2023年6月博士毕业,就职阿里达摩院。

金琴,中国中国人民大学信息学院计算机系教授,多媒体计算实验室(aim3)负责人。主要研究领域为多媒体智能计算、人机交互。

亚博888 copyright © 2015 school of information, renmin university of china. all rights reserved.
亚博888的版权所有中国人民大学信息学院